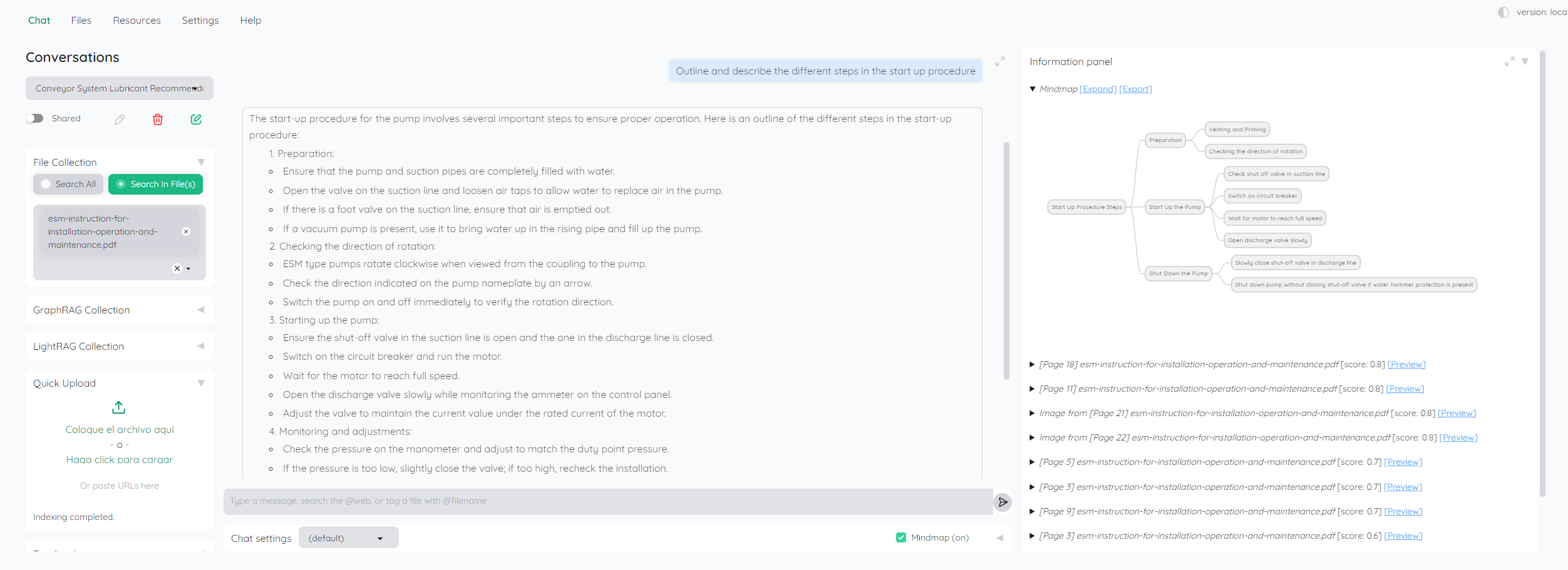
Automating engineering reports with fine-tuned language models represents a transformative advancement in engineering documentation. Traditional reporting processes, often burdened by repetitive data entry, formatting inconsistencies, and human error, can be significantly streamlined through the integration of natural language processing (NLP) techniques.
Fine-tuned language models offer a powerful solution by enabling the generation of context-aware, structured, and coherent reports with minimal human intervention. These models are trained on domain-specific datasets, ensuring that technical jargon, engineering standards, and industry conventions are accurately incorporated into the output. By leveraging pre-trained transformers and refining them with engineering-specific data, these models learn to produce reports that align with best practices and regulatory requirements.
Data ingestion serves as a foundational step in the automation process. Engineering reports often aggregate information from various sources, including sensor data, CAD models, simulation results, and manual inputs. Fine-tuned models can be designed to extract relevant data from structured and unstructured sources, interpreting numerical values, trend analyses, and operational conditions. The integration of these models with engineering software and databases ensures seamless data retrieval and enhances report accuracy.
Contextual understanding is another critical aspect of automation. Unlike rule-based reporting systems, which rely on predefined templates, fine-tuned language models dynamically adjust narratives based on the data they receive. This adaptability is essential for complex engineering disciplines where variations in design, material selection, and performance parameters demand nuanced reporting. The model’s ability to analyze previous reports and adapt its language style ensures consistency while accommodating new information.
Ensuring compliance with industry regulations and standards remains a priority in automated reporting. Fine-tuned models can be trained on compliance documents and guidelines, enabling them to cross-reference generated reports with regulatory requirements. This feature minimizes the risk of non-compliance by automatically flagging inconsistencies and suggesting modifications. Additionally, automated quality control mechanisms can be implemented to validate numerical accuracy and logical coherence within the generated content.
Enhancing human oversight through interactive feedback loops further optimizes the automation process. Engineers can review, modify, and fine-tune generated reports, allowing the model to learn from corrections and progressively improve its output. Active learning techniques, where the model retrains on validated inputs, ensure continuous refinement and adaptation to evolving engineering practices.
Deploying fine-tuned language models in engineering workflows requires robust integration with existing digital ecosystems. Cloud-based platforms, API-driven architectures, and interoperability with engineering tools facilitate smooth adoption. Security considerations, including data encryption and access control, must be addressed to protect sensitive engineering information. Additionally, computational efficiency is a crucial factor, as real-time or near-real-time report generation demands optimized inference times without compromising accuracy.
The adoption of fine-tuned language models in engineering report automation offers substantial benefits, including increased efficiency, reduced errors, and enhanced standardization. By minimizing manual effort and ensuring consistency, engineers can focus on high-value tasks such as analysis, innovation, and decision-making. As machine learning models continue to evolve, the future of engineering documentation will be increasingly autonomous, intelligent, and adaptive to the dynamic needs of the industry.